
Spark sees 10x improvement in Filecoin retrievability
| Patrick Woodhead | |
| ProductSpark | |
| Published | |
| Patrick Woodhead | |
| On April 18th 2024, the overall Filecoin retrieval success rate (RSR), as measured by Spark, was 1.22%. Many Storage Providers were simply not serving retrievals. On the 25th September 2024, Spark measured the overall Filecoin RSR at 12.8%, a 10.5x improvement. | |
 | |
| Spark sees 10x improvement in Filecoin retrievability |
On April 18th 2024, the overall Filecoin retrieval success rate (RSR), as measured by Spark, was 1.22%. Many Storage Providers were simply not serving retrievals. On the 25th September 2024, Spark measured the overall Filecoin RSR at 12.8%, a 10.5x improvement.
Where We Were In July
At Fil Dev Summit in Brussels in July 2024, the Space Meridian team announced that we’d seen a potential up-trend in the Filecoin retrieval success rate (RSR), as measured by Spark.
This uptick was caused by allocators using the Spark RSR scores to inform their datacap allocation decisions, and so Storage Providers (SPs) were suddenly incentivised to serve retrievals for public data they were storing, in order to win more datacap going forward.
The flow of datacap is a complex topic for the uninitiated, so we can simply say that there was suddenly an incentive for SPs to start serving retrievals from May 2024, and we began to measure an improvement shortly afterwards.
Where We Are Now
The below chart shows the Filecoin retrieval success rate as measured by Spark between mid April and the end of September 2024.
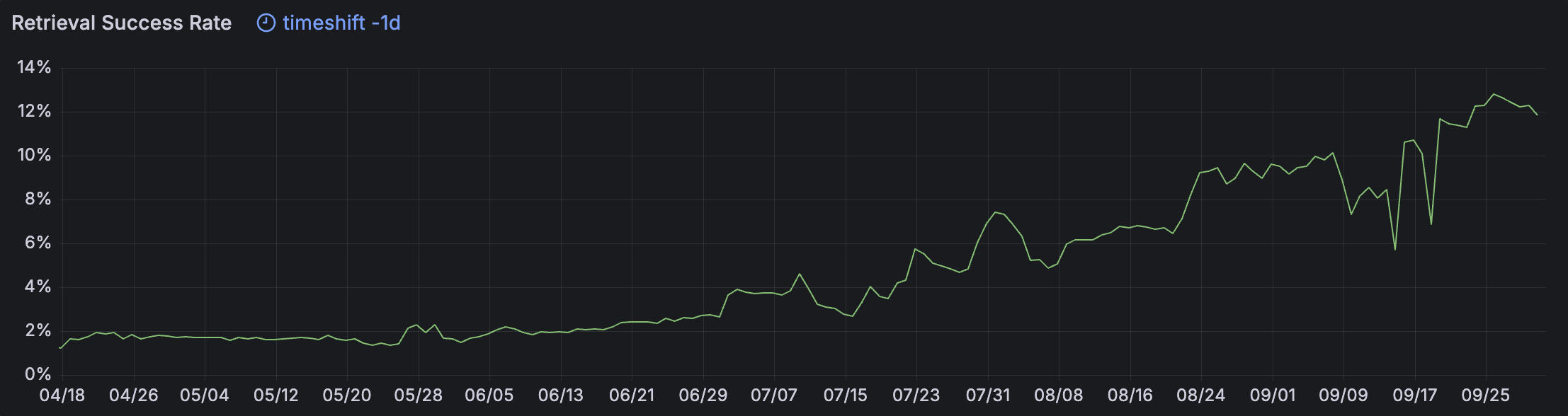
Since we first noticed the improvement in Brussels in July, we are pleased to report that we’ve seen the up-trend continue, with an increasing number of SPs achieving a high Spark RSR.
On April 18th 2024, the overall Filecoin retrieval success rate (RSR) as measured by Spark was 1.22%. Many Storage Providers were simply not serving retrievals. On the 25th September 2024, Spark measured the overall Filecoin RSR at 12.8%, a 10.5x improvement. 🚀
The improvement by SPs can be visualised in another way in the following chart, which shows the number of Filecoin SPs whose Spark RSR score falls into certain buckets.
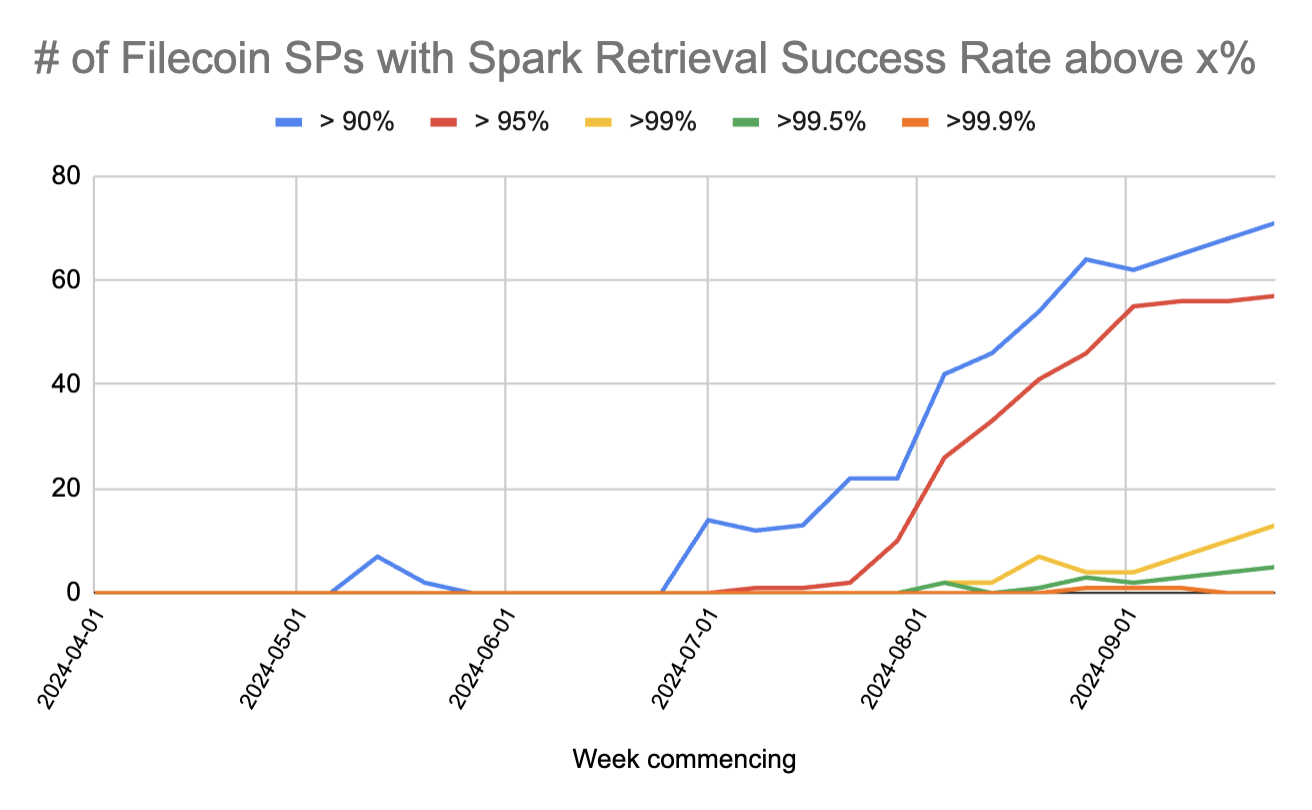
In April 2024, Spark recorded zero SPs with a retrieval success rate above 90% over a weekly period, which we call “one nine retrievability”.
By the end of September 2024, there were over 70 SPs with one nine retrievability, and 13 SPs with two nines retrievability (>99%). There was even a few weeks where we recorded an SP with three nines retrievability (>99.9%). For comparison, AWS S3’s availability SLA is four nines, 99.99%.
Where We Are Going
We would love to see this trend of improving retrievability continue. As we build more trust in the availability and retrievability of public data stored on Filecoin via the checks performed by the Spark protocol, Filecoin data clients will have more interest in the Filecoin network beyond just archival storage, thus improving the overall product market fit of the network.
- In Q4, we will ship Spark compatibility with DDO deals to keep Spark up to date with the latest developments in the way people are storing data on Filecoin.
- We are also researching how to incentivise Spark retrievals without the dependency on the FIL+ datacap program.
- There has also been increasing demand to use the Spark API, with Spark data populating an array of Filecoin related dashboards, like Starboard.
- We would also like to put Spark scores on chain so that they can be referenced in smart contracts.
Please reach out if you would like to learn more about Spark!
More posts like this
Posts
| Filecoin Spark: Common Critiques | EngineeringSpark | Published | Patrick Woodhead | Patrick Woodhead | A Review of Current Common Critiques of Filecoin Spark |  | Filecoin Spark: Common Critiques | |||
| Spark sees 10x improvement in Filecoin retrievability | ProductSpark | Published | Patrick Woodhead | Patrick Woodhead | On April 18th 2024, the overall Filecoin retrieval success rate (RSR), as measured by Spark, was 1.22%. Many Storage Providers were simply not serving retrievals. On the 25th September 2024, Spark measured the overall Filecoin RSR at 12.8%, a 10.5x improvement. | | Spark sees 10x improvement in Filecoin retrievability | |||
| How SPARK Retrieves Content From Filecoin | EngineeringSpark | Published |  Miroslav Bajtoš Miroslav Bajtoš | Miroslav Bajtoš | In the previous posts, we explained how SPARK samples Filecoin deals and how SPARK discovers content stored in those deals. In the final post of this series, we will explain how SPARK tests whether the content can be retrieved. |  | How SPARK Retrieves From Filecoin | |||
| Spark Roadmap H2 2024 | EngineeringSpark | Published | Patrick Woodhead | Patrick Woodhead | The roadmap for the Spark Protocol in H2 2024 |  | Spark Roadmap H2 2024 | |||
| How SPARK Discovers Content Stored in FIL+ Deals | EngineeringSpark | Published | Miroslav Bajtoš | Miroslav Bajtoš | SPARK is checking whether public content stored on Filecoin can be retrieved. This post explains how SPARK Spark discovers the CIDs (content identifiers) of the data stored in Filecoin deals. |  | How Spark Discovers Content Stored in FIL+ Deals | |||
| How SPARK Samples Filecoin Deals | EngineeringSpark | Published | Miroslav Bajtoš | Miroslav Bajtoš | SPARK is checking whether public content stored on Filecoin can be retrieved. This post explains how SPARK samples Filecoin deals to find content that is expected to be publicly retrievable. |  | How SPARK Samples Filecoin Deals | |||
| Ethers v5 and Colossal Gas Overspending | Engineering | Published |  Julian Gruber Julian Gruber | Julian Gruber | The popular JavaScript library Ethers v5 can overpay FVM smart contract calls by 6000x. A single contract call can cost >2FIL instead of negligible 0.0003 FIL. |  | Ethers v5 and Colossal Gas Overspending | |||
| How we reduced memory usage by 90% | EngineeringSpark | Published | Miroslav Bajtoš | Miroslav Bajtoš | Four easy changes reduced the total memory usage of Spark’s Node.js backend from 4+ GB to ~360 MB: Convert plain data objects to class instances. De-duplicate immutable string values. Carefully choose how you calculate percentiles. Represent timestamps as numbers. |  | How we reduced memory usage by 90% | |||
| Optimising Performance of Spark's Postgres Database | EngineeringSpark | Published | Miroslav Bajtoš | Miroslav Bajtoš | Setting up observability for Postgres performance requires a bit of work, but it gives you valuable insights into the performance of your database. |  | Optimising Performance of Spark's Postgres Database |